Galaxy
This documentation was written for deploying Galaxy on the Penn State University systems. Keep this in mind if you reference these instructions as they may be out of date.
Dependencies
- Assuming you have installed the required development tools for Mac OS
- Install samtools.
brew install samtools
- Install yarn.
brew install yarn
Installing Galaxy
It is recommended that you clone galaxy to your ~/Desktop, so that GALAXY's internal paths are shorter and avoid conda throwing any errors that your path exceeds the maximum characters for tool install paths
here we are going to work with 17.09 release of GALAXY.
- Open a
terminaland clone GALAXY to your~/Desktop.
cd ~/Desktop
git clone -b release_17.09 https://github.com/galaxyproject/galaxy.git
- Start GALAXY
cd galaxy
sh run.sh
Note that when you are starting galaxy for the first time, it takes some time to install required internal dependencies and setup its internal database. Once its gone through it, you should be able to see the start up page.
- Congratulations you have successfully installed GALAXY on your local machine.
| Useful resources & tutorials |
|---|
| Get galaxy |
| Learn galaxy |
| Dagobah training |
Configuring Galaxy
Setting up an Admin
galaxy.ini file contains most of the configurations to your local galaxy. It has some predefined defaults which you might want to re-think before changing anything.
We will be using cegr@psu.edu as the default admin, so that it can be used to integrate with PEGR in the PEGR tutorial, where we use our local galaxy to send out information to PEGR
- Make sure your Galaxy is not online, before making any changes to configuration.
- Open your galaxy folder in
Finderon your mac. you should see aconfig/folder. - Inside the
config/, you will find agalaxy.ini.samplefile. - Copy the
galaxy.ini.samplewithin the same folder and rename the copied file togalaxy.ini - Open the
galaxy.iniin a text editor of your choice. - Search for the line that starts with
admin_usersand addcegr@psu.edu
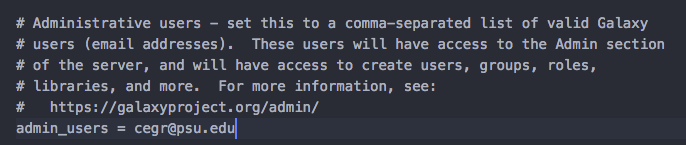
Above image shows the change. make sure you have edited ~/Desktop/galaxy/config/galaxy.ini
- Start your Galaxy now,
sh run.sh - Click on
Usermenu and then clickregister - You should see a registration page as below
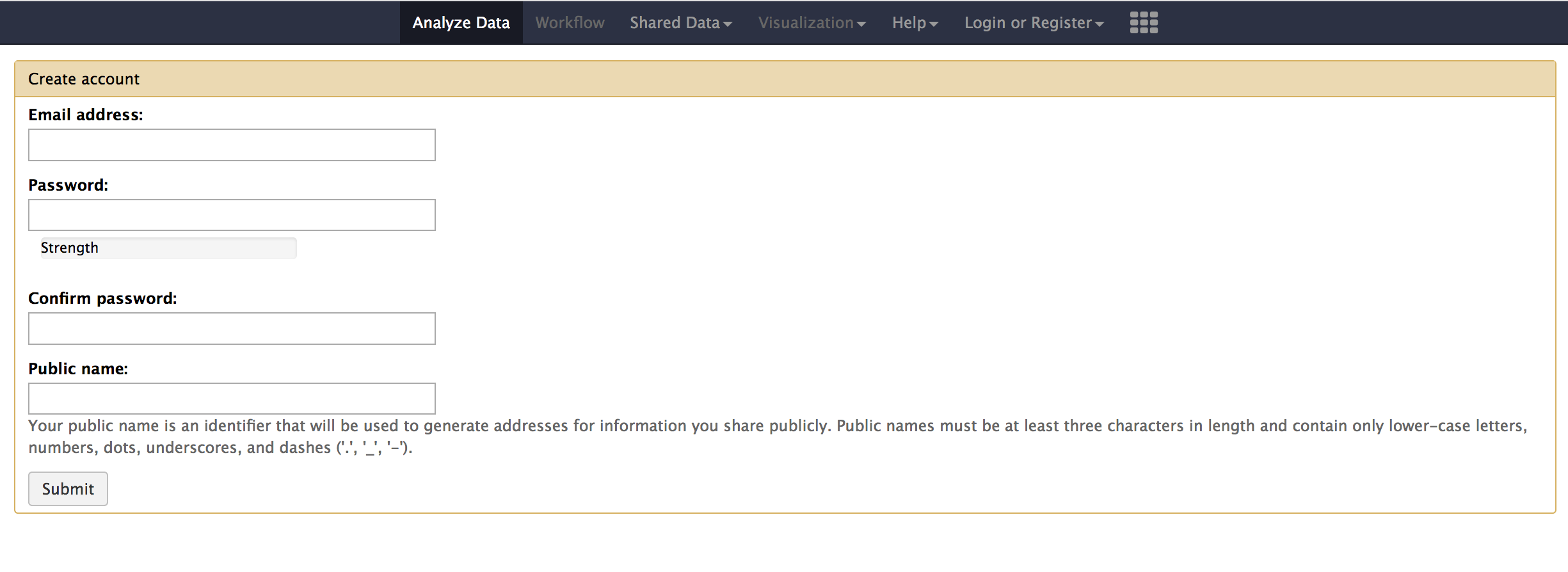
- Enter
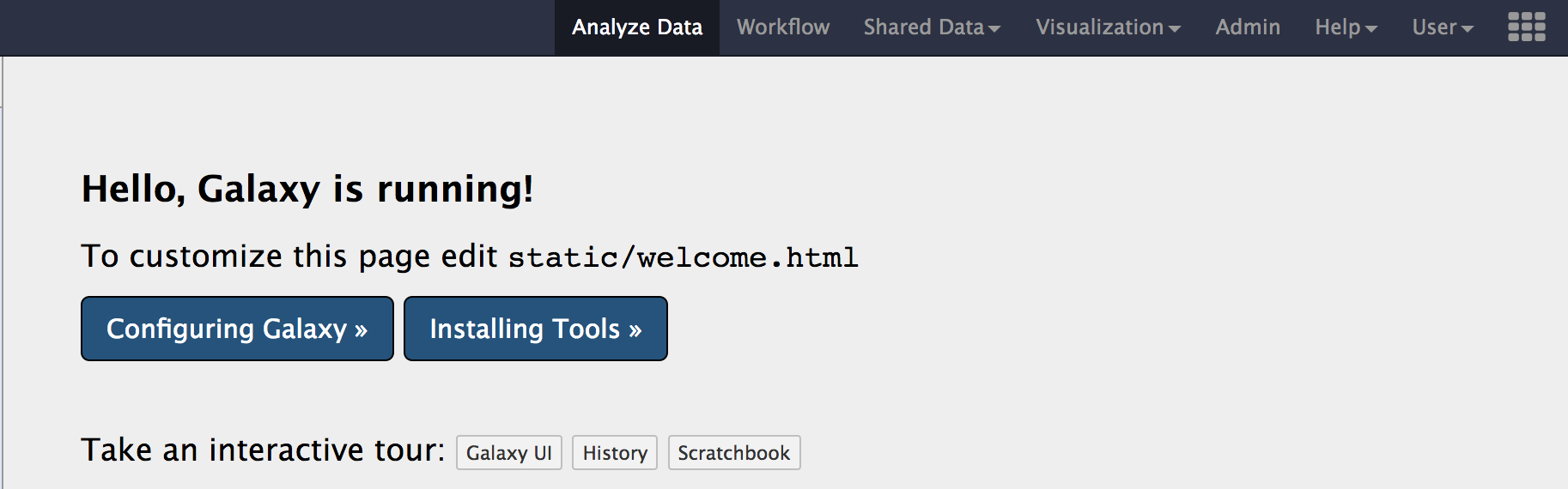
cegr@psu.eduas the email address and choose apassword,public nameof your choice. - Once you login, you should now have the
Adminmenu show up on the menu bar on the top.
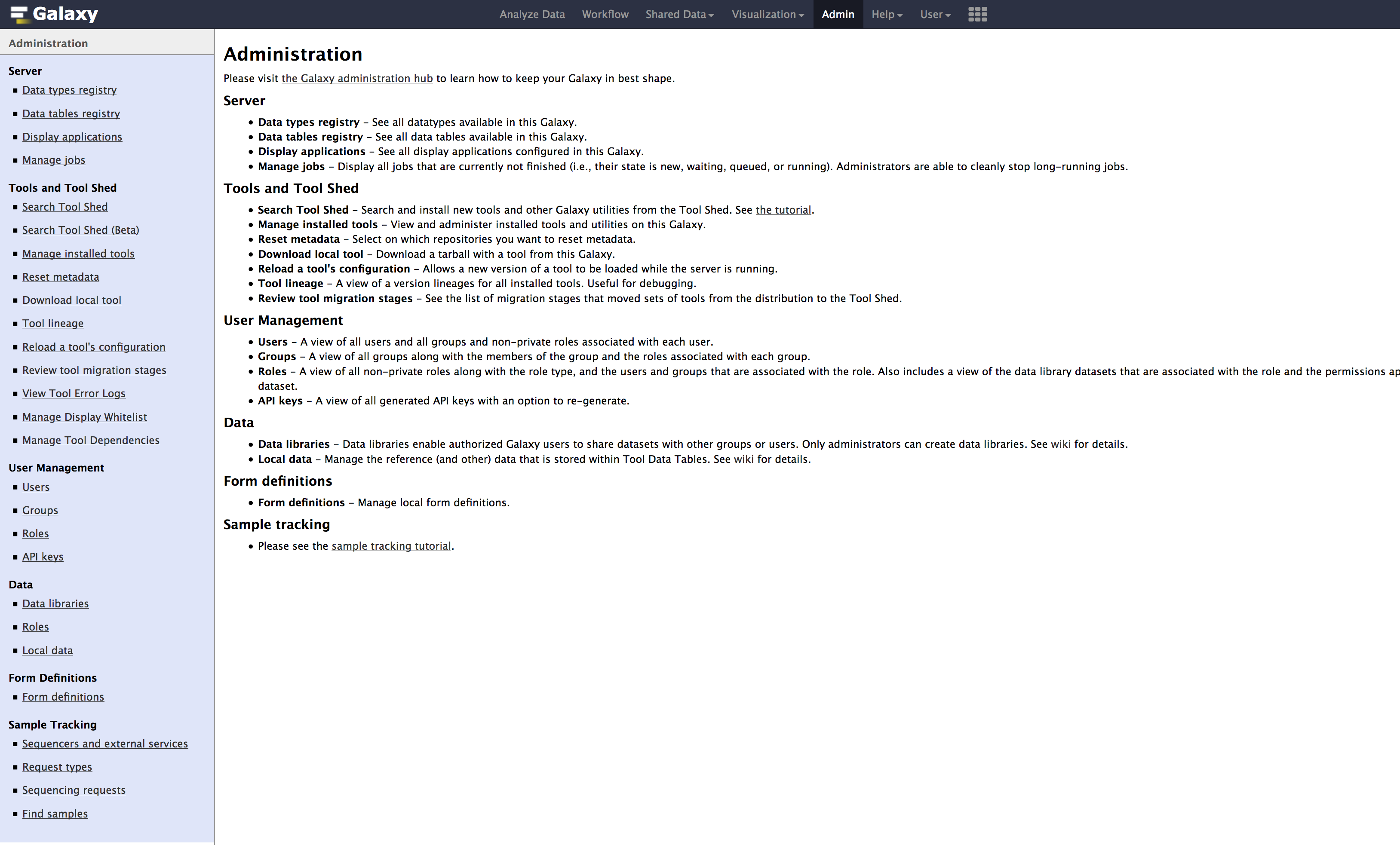
- When you click on the
Admintab, you should see the below page.
Adding Custom Genomes
sacCer3_cegr is the customized yeast genome we are using within the lab. Though the differences are few (to the best of my knowledge), but are very important to keep in mind while performing general data analysis. This genome deviates from the UCSC recommendations
sacCer3_cegr contains 2-micron regions & chromosome naming is using decimal number instead of roman numerals. This causes some disadvantages to use tools like bedGraphToBigWig, etc.
- Click on
Admintab, then underTools and Tool Shedsection, click onSearch Tool Shed
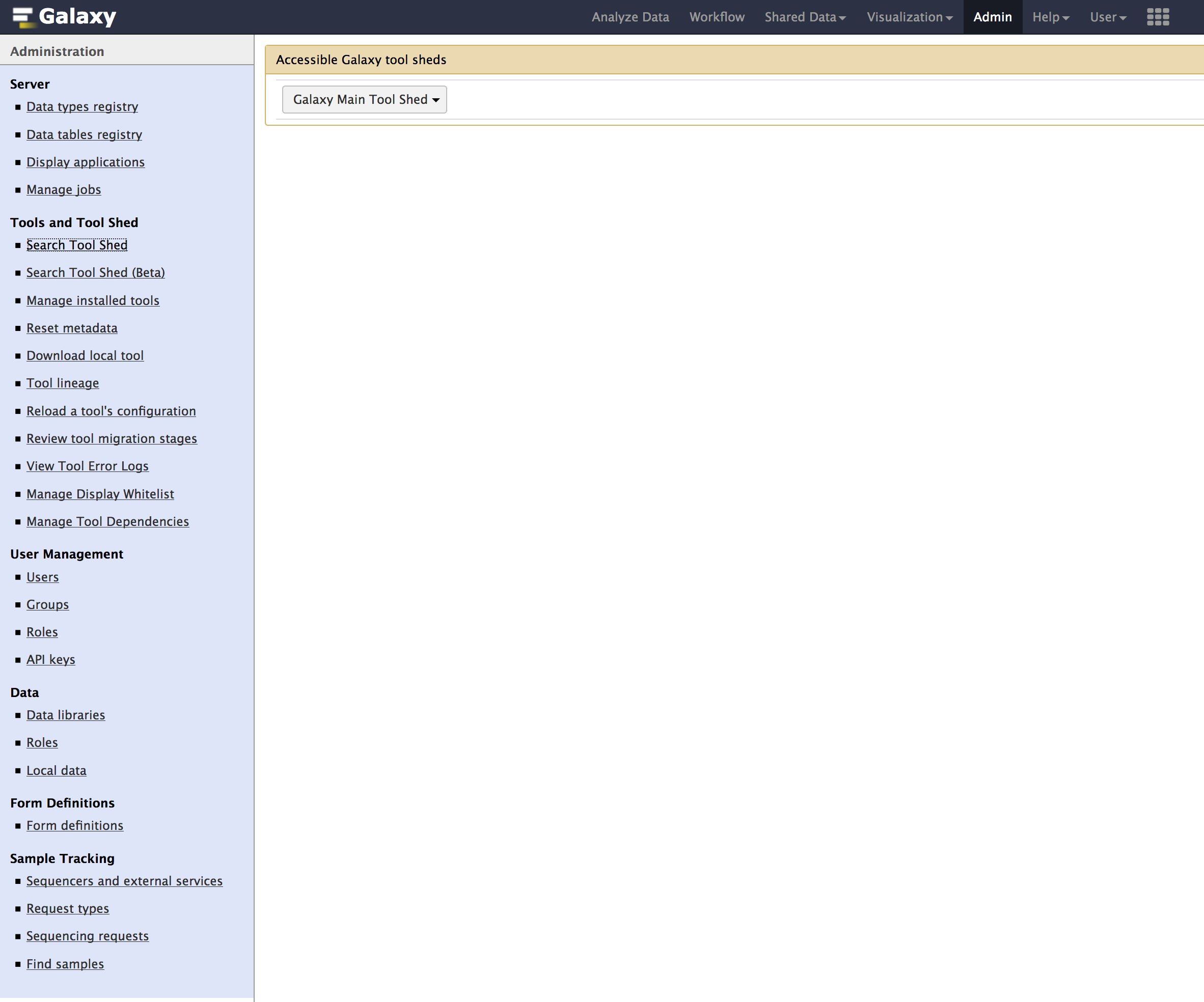
- Click on
Galaxy Main Tool Shed
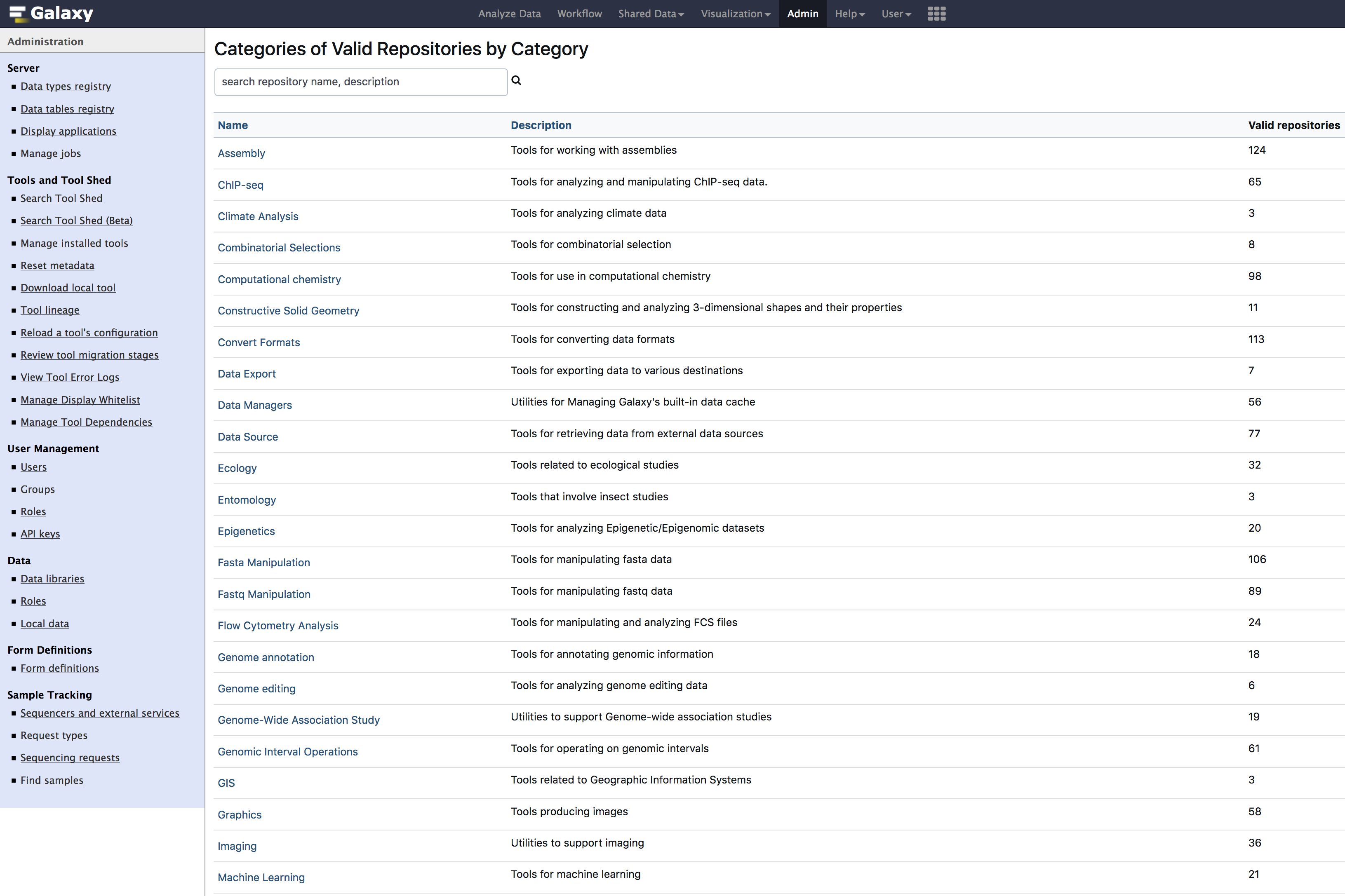
- Search & Install below tools. you can copy and paste below tool names into the search box.
| Tool Name |
|---|
data_manager_bwa_mem_index_builder |
data_manager_fetch_genome_dbkeys_all_fasta |
data_manager_sam_fasta_index_builder |
data_manager_twobit_builder |
- Below images previews the steps for installing a tool.

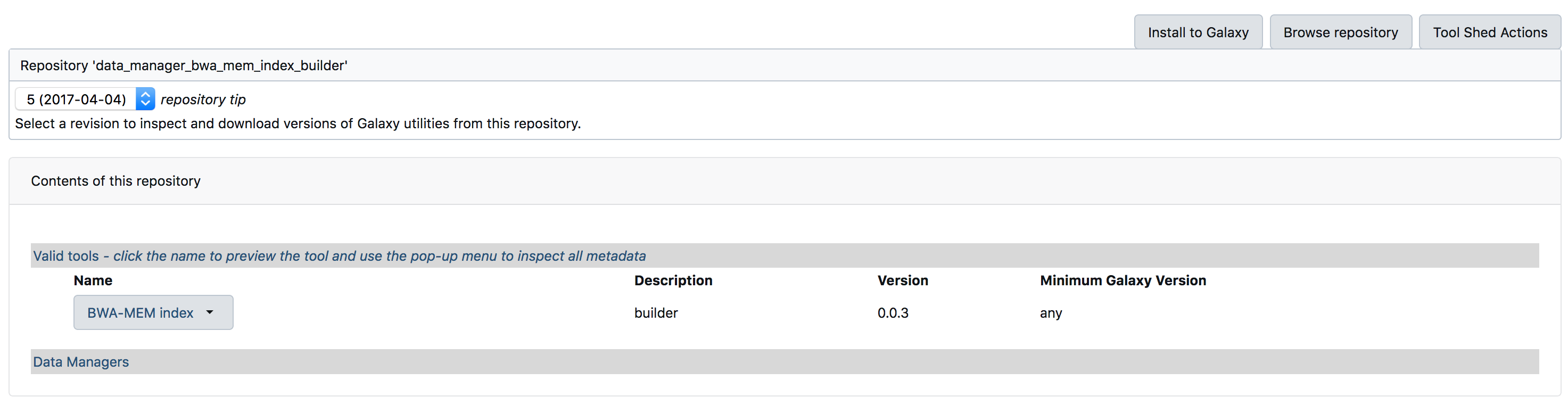
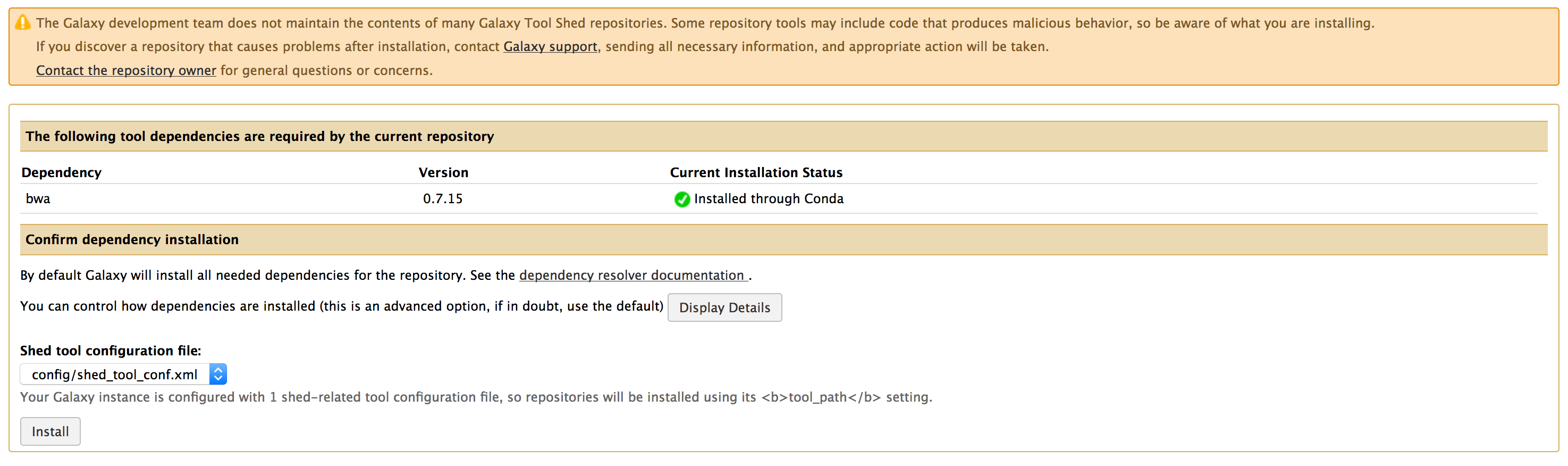
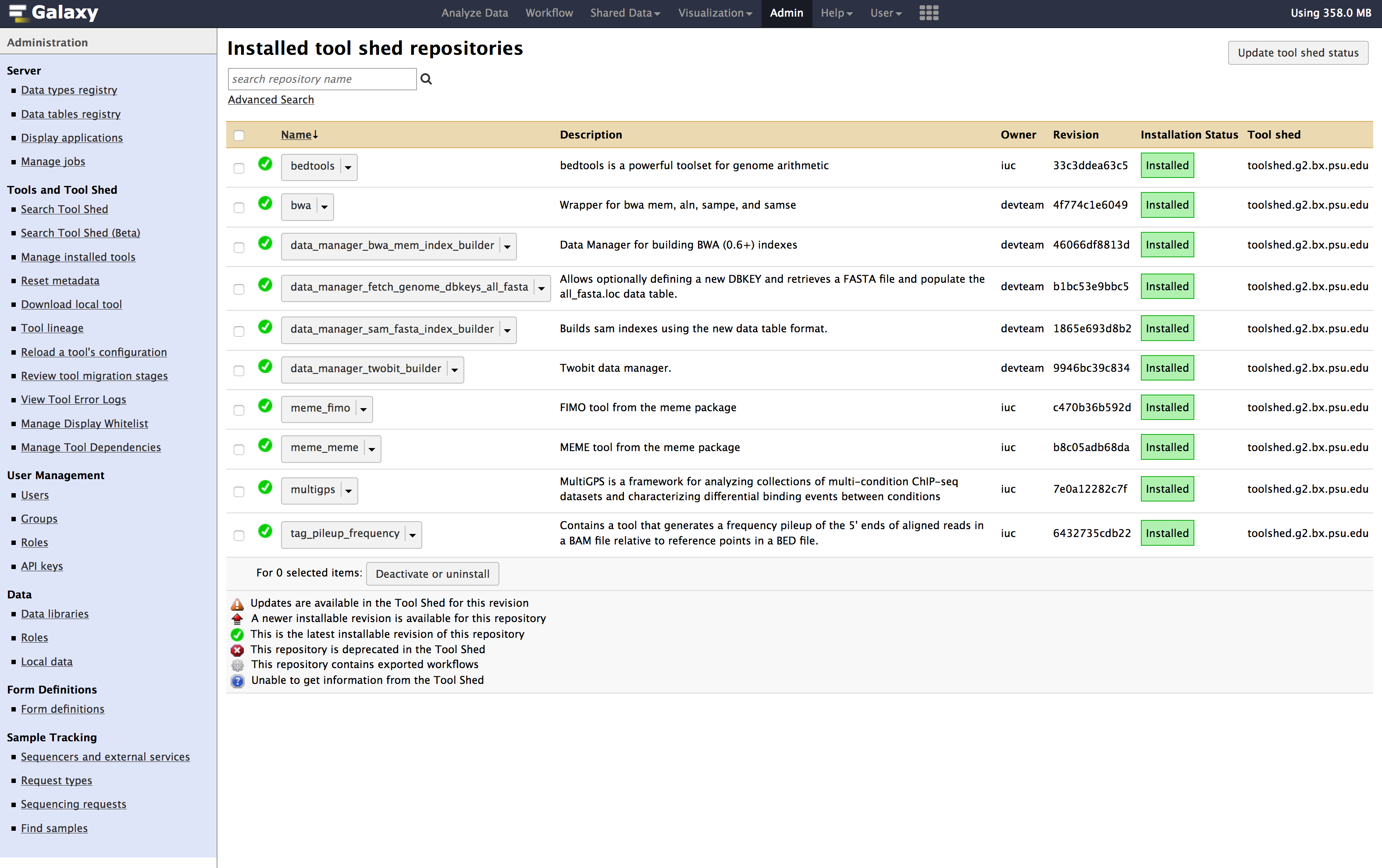
- Once you have installed all the above tools, You can verify the installation at
Admin > Tools and Tool shed > Manage installed tools
- Download the
sacCer3_cegrgenome from link removed:./image/data/sacCer3_cegr.fa - Upload the file you downloaded above into galaxy, using the
upload buttonlocated on the tools menu, as shown in the image below.
- Once you have uploaded, you should see the file appear in the “history pane” on your right.
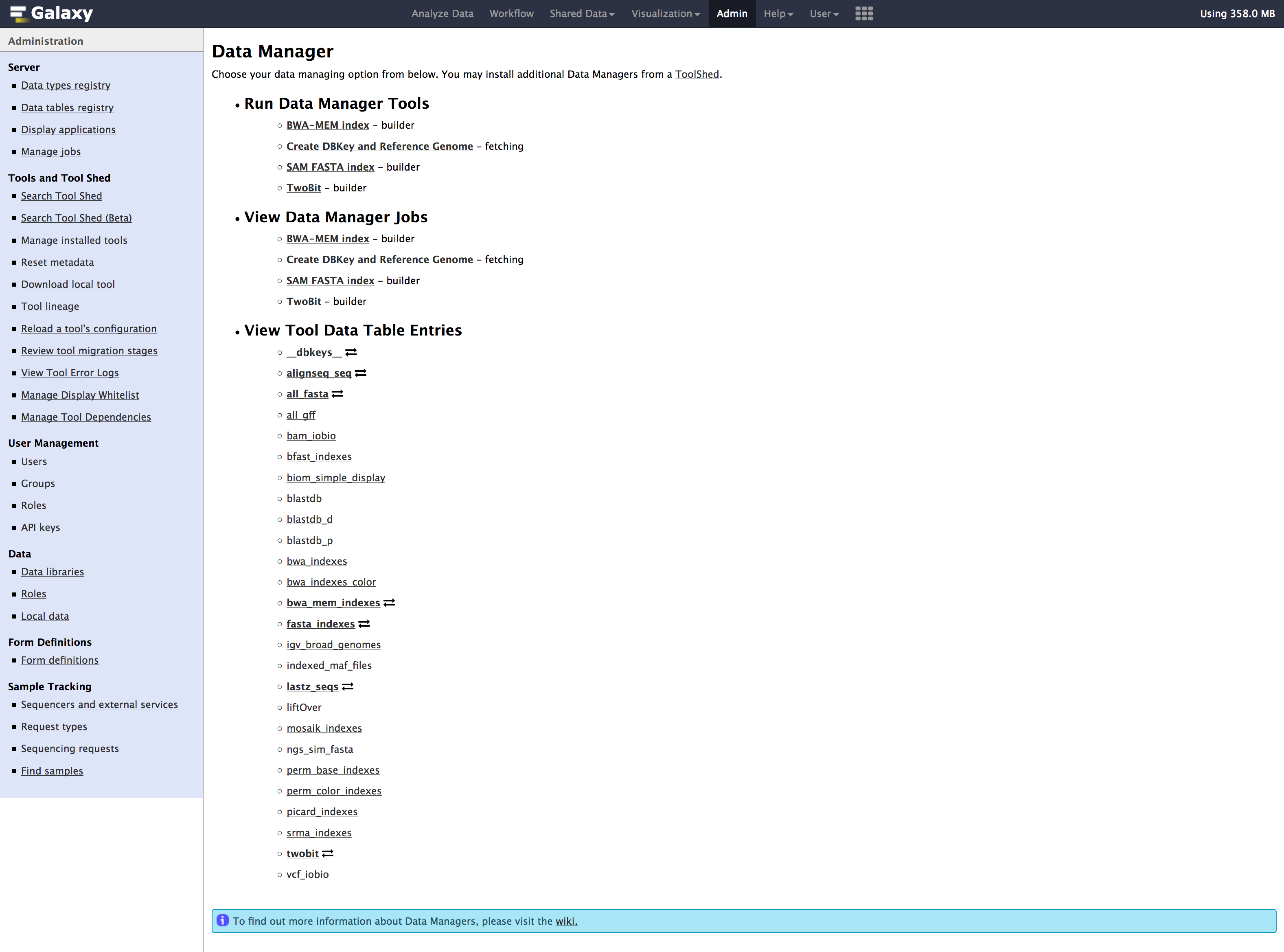
- Go to
Admintab, underDatasection, Click onLocal datato getData manager
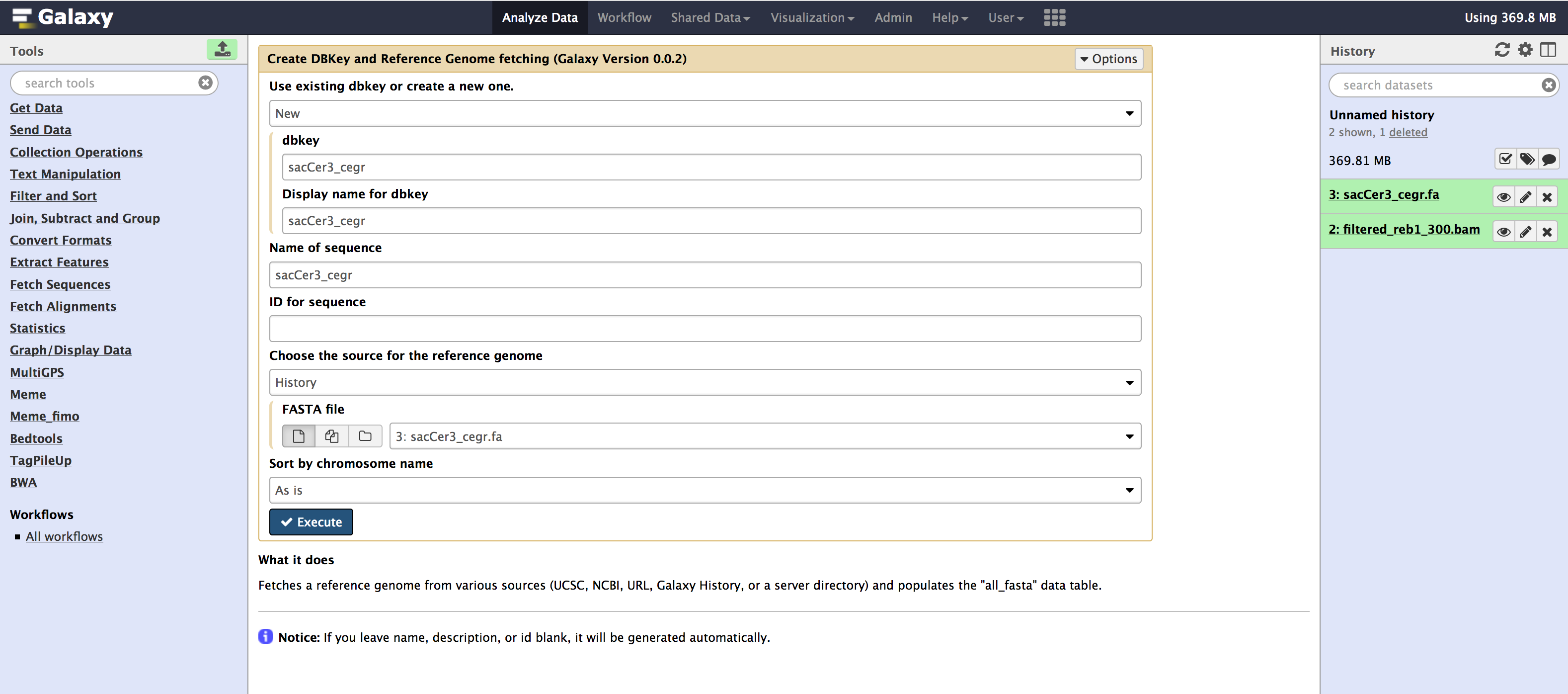
- We need to run below tools one after the other in the exact order mentioned below:
| Tool | Order |
|---|---|
| Create DBkey and reference geneome | #1 |
| TwoBit | #2 |
| BWA-MEM | #3 |
| SAM Fasta | #4 |
All these tools are available from the Admin > Data > Local data section. Below are images for step-by-step execution of above tools in the same order. use them to fill out any default information that is required and follow along
- You can specify sequence name to be
sacCer3_cegrand leave everything as default in all the tools.
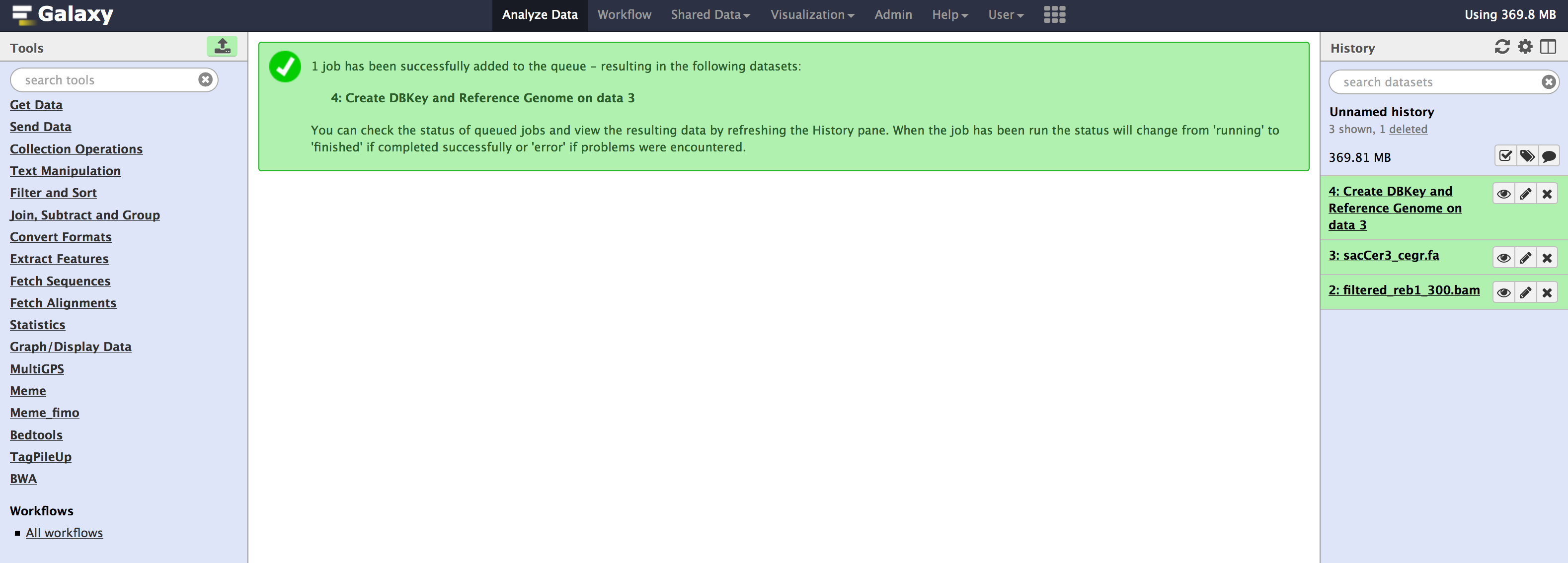
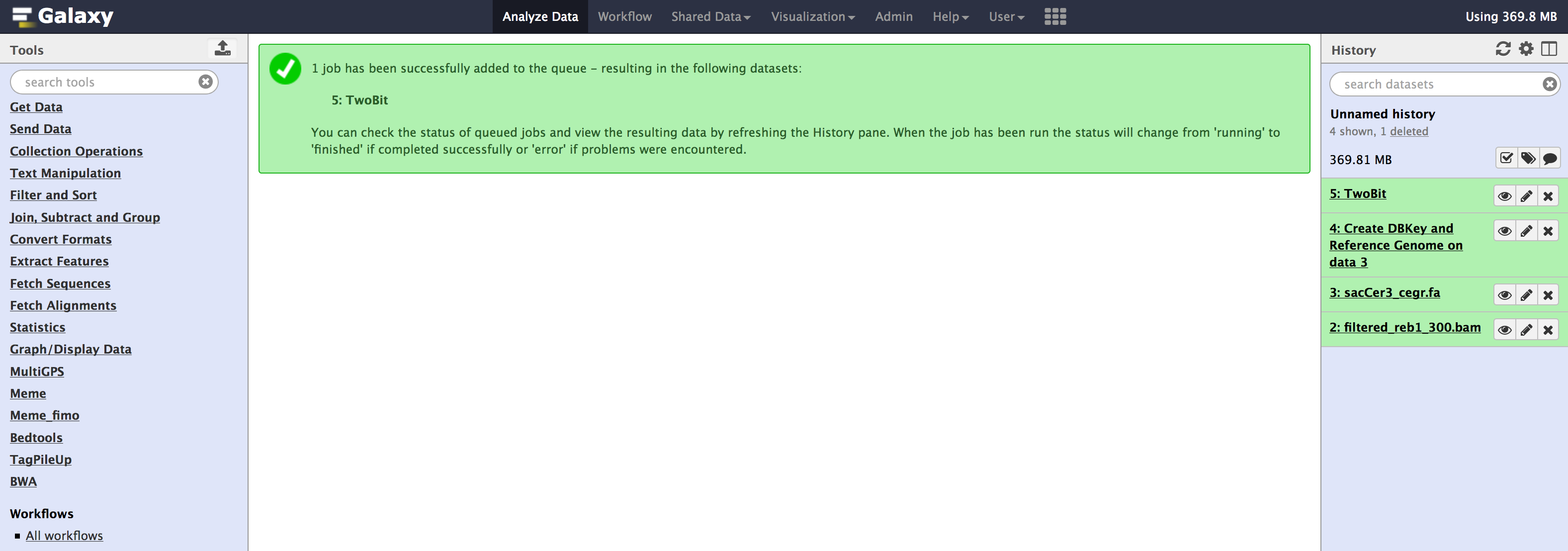
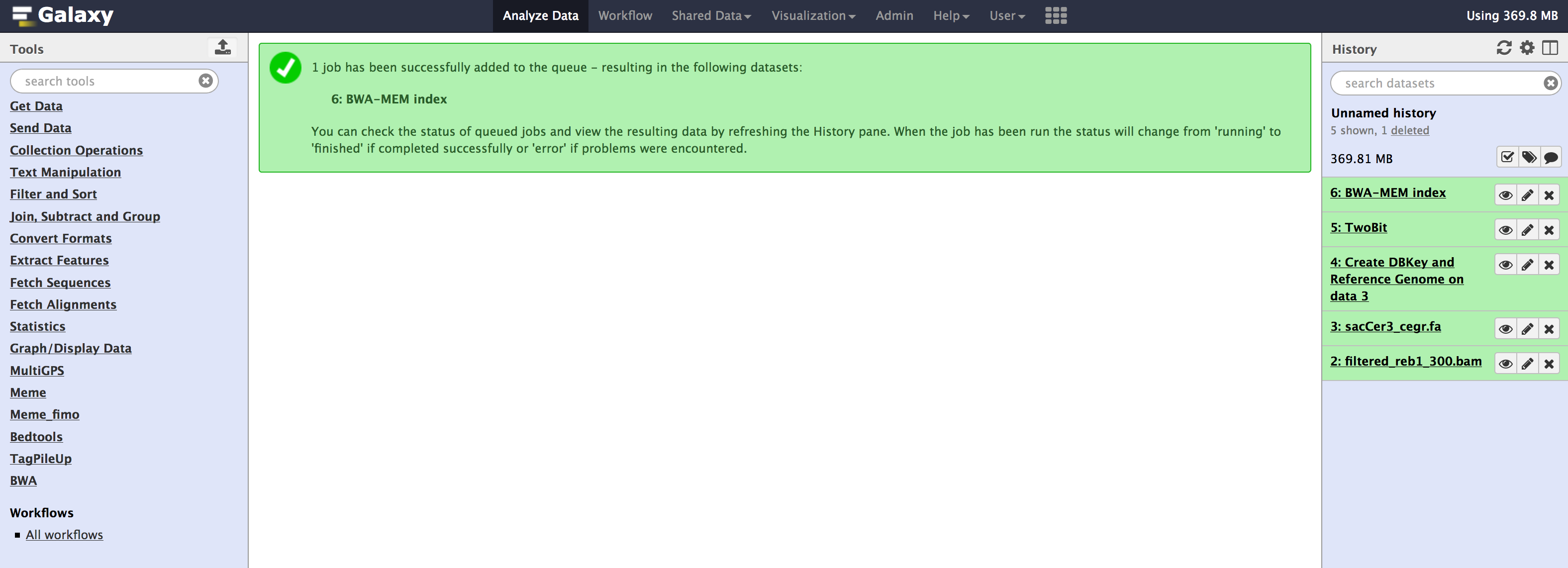
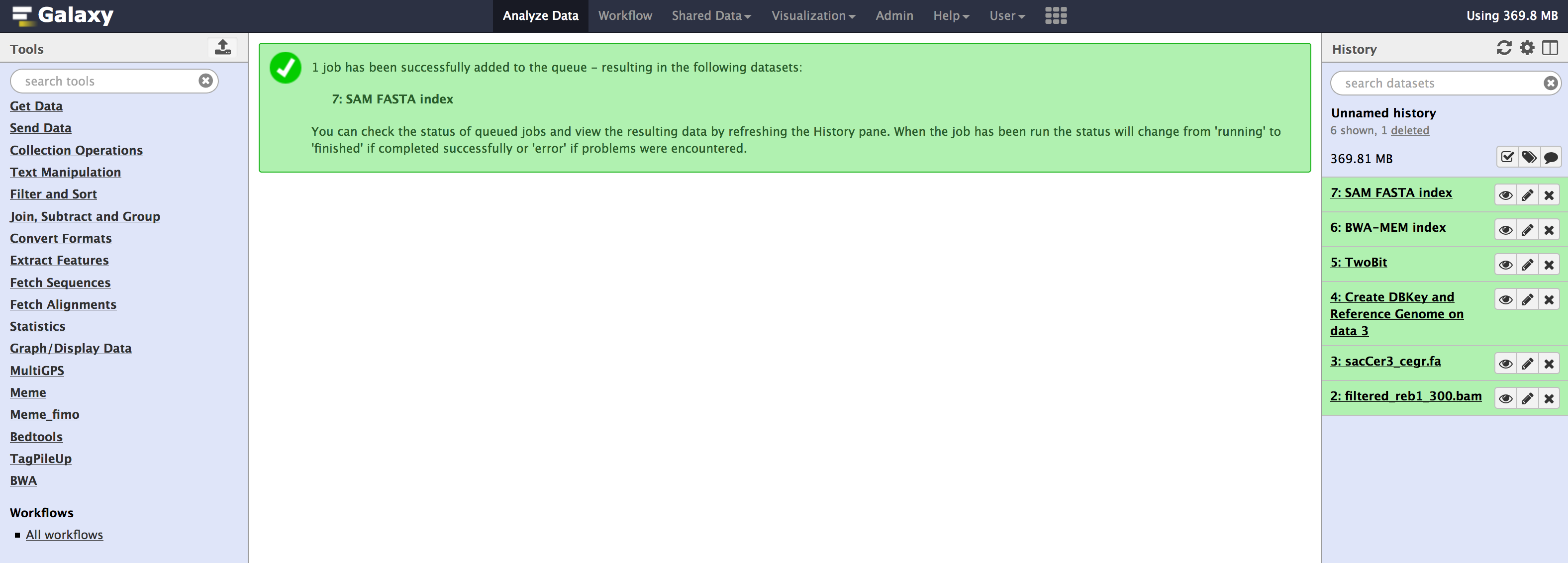
- Once you have run all the tools, you need to check couple of things that populate in the internal database of galaxy. You can check that information from your
Adminpage. - Go to
Admin > Data > Local datasection, underView Tool Data Table Entries. Click on__dbkeys__you should see something like below.
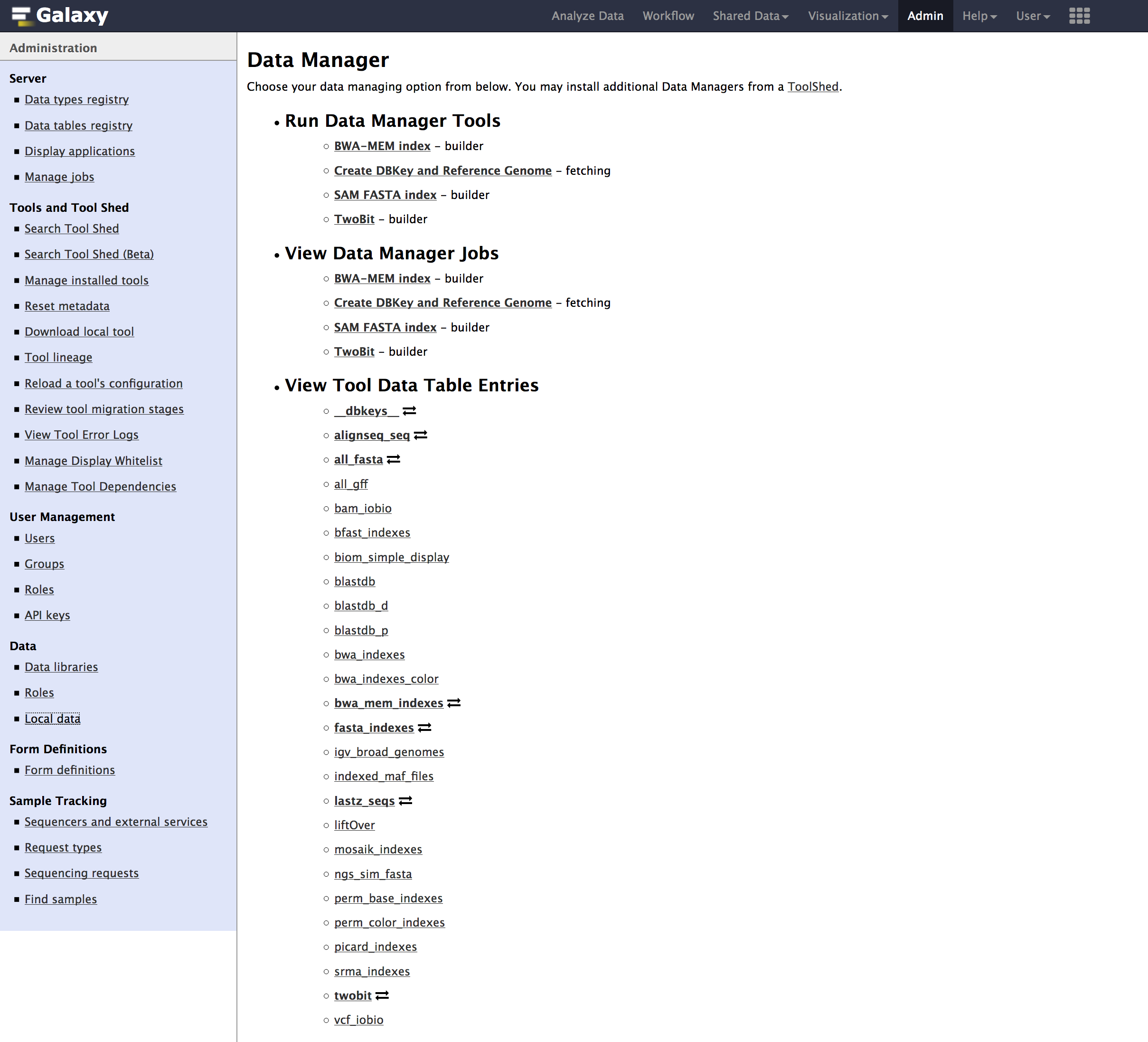

- Similarly check
all_fasta,twobit,bwa_mem_indexes. All of them should contain an entry forsacCer3_cegr. Path could be different in your case.



- If your able to see similar results as above images.
Congratulations!you have successfully added a custom genome build into your galaxy.
Importing ChIP-exo Workflow
We will install the core-sequencing workflow that the lab uses to analyze all the samples that are sequenced. This pipeline is run to create BAM files, peak calling using genetrack and MEME motif analysis.
- Download the workflow file link removed:
./image/data/Galaxy-Workflow-paired_002.ga - Once you have downloaded the workflow. You can
importit into your local galaxy from theWorkflowtab using theupload or import workflowbutton located beside the search bar. (see image below).

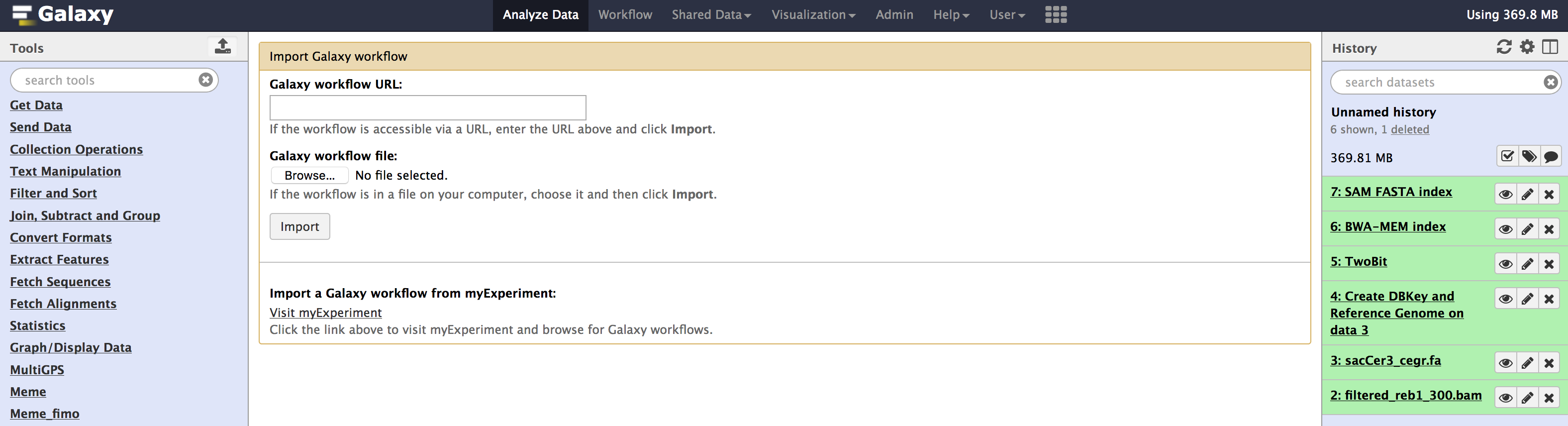
- Once you have selected the workflow file and clicked
import. You might see some errors such as below. Nothing to worry, the error messages is caused by tools that are not yet installed & are important for the workflow to run in your galaxy.
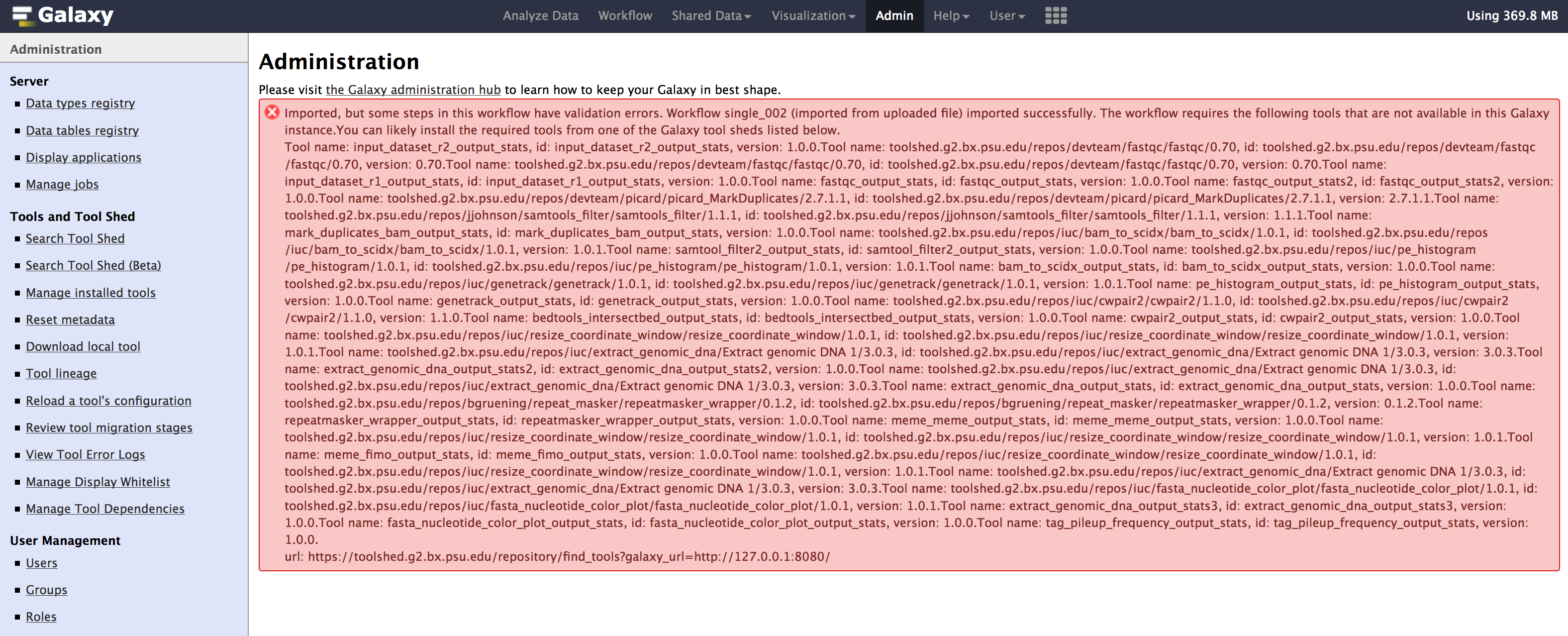
- Click on
editoption under the workflow drop-down menu. To find out the missing tools. - You need to install each tool manually from toolshed. Go to
Admin > Tools and Tool Shed > Search toolShedto search and install each tool that is missing.
Few tools have their toolnames in the workflow that end with output_statistics. These are the tools that are not available on Galaxy toolshed and need to be side-loaded separately, which we will do in the next section. so for now, you can ignore installing these tools and their errors.
Integrating CEGR output_statistics
This section is similar to adding custom tools into Galaxy, here is a (tutorial). cegr-galaxy repo contains other important scripts that are used to run the core-sequencing pipeline on production galaxy. The repo has a README file detailing the usage of each script.
Clone the repository containing the CEGR tools from seqcode/cegr-galaxy
git clone https://github.com/seqcode/cegr-galaxy.git
Copy the entire
cegr_statisticsfolder to this locationgalaxy/tools/within your local galaxy.Open
galaxy/config/tool_conf.xmlin a text editor of your choice.
If the above file doesn't exist, there should be a file in the same config directory called tool_conf.xml.main, copy and rename the file to tool_conf.xml
- Add below lines at the end of file, within the
</toolbox>tag.
<section id="cegr_tools" name="CEGR">
<tool file="cegr_statistics/bam_to_scidx_output_stats.xml" />
<tool file="cegr_statistics/bedtools_intersectbed_output_stats.xml" />
<tool file="cegr_statistics/bwa_mem_output_stats_single.xml" />
<tool file="cegr_statistics/cwpair2_output_stats.xml" />
<tool file="cegr_statistics/extract_genomic_dna_output_stats.xml" />
<tool file="cegr_statistics/extract_genomic_dna_output_stats2.xml" />
<tool file="cegr_statistics/extract_genomic_dna_output_stats3.xml" />
<tool file="cegr_statistics/fasta_nucleotide_color_plot_output_stats.xml" />
<tool file="cegr_statistics/fastqc_output_stats.xml" />
<tool file="cegr_statistics/fastqc_output_stats2.xml" />
<tool file="cegr_statistics/genetrack_output_stats.xml" />
<tool file="cegr_statistics/input_dataset_r1_output_stats.xml" />
<tool file="cegr_statistics/input_dataset_r2_output_stats.xml" />
<tool file="cegr_statistics/mark_duplicates_bam_output_stats.xml" />
<tool file="cegr_statistics/meme_fimo_output_stats.xml" />
<tool file="cegr_statistics/meme_meme_output_stats.xml" />
<tool file="cegr_statistics/pe_histogram_output_stats.xml" />
<tool file="cegr_statistics/repeatmasker_wrapper_output_stats.xml" />
<tool file="cegr_statistics/repeatmasker_wrapper_output_stats2.xml" />
<tool file="cegr_statistics/samtool_filter2_output_stats.xml" />
<tool file="cegr_statistics/tag_pileup_frequency_output_stats.xml" />
</section>
The above lines informs GALAXY, where it can find the tools and corresponding toolwrappers
- The file
galaxy/config/tool_config.xmlshould look something like below:
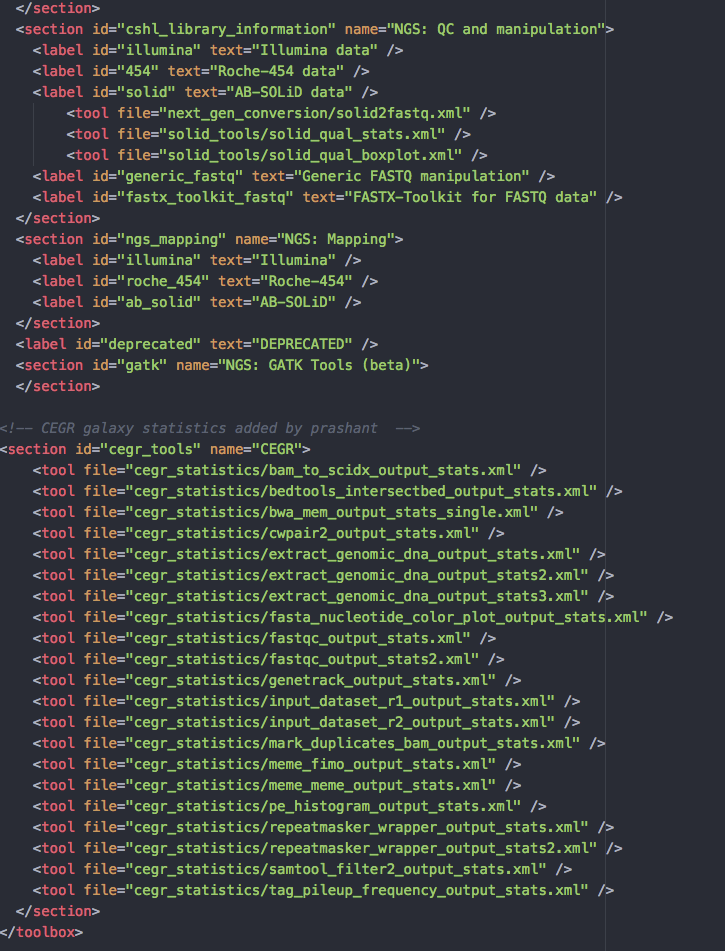
- Save the file and restart Galaxy. You should now see these tools appear under
Toolsmenu within galaxy'sAnalyze Datatab similar to below.
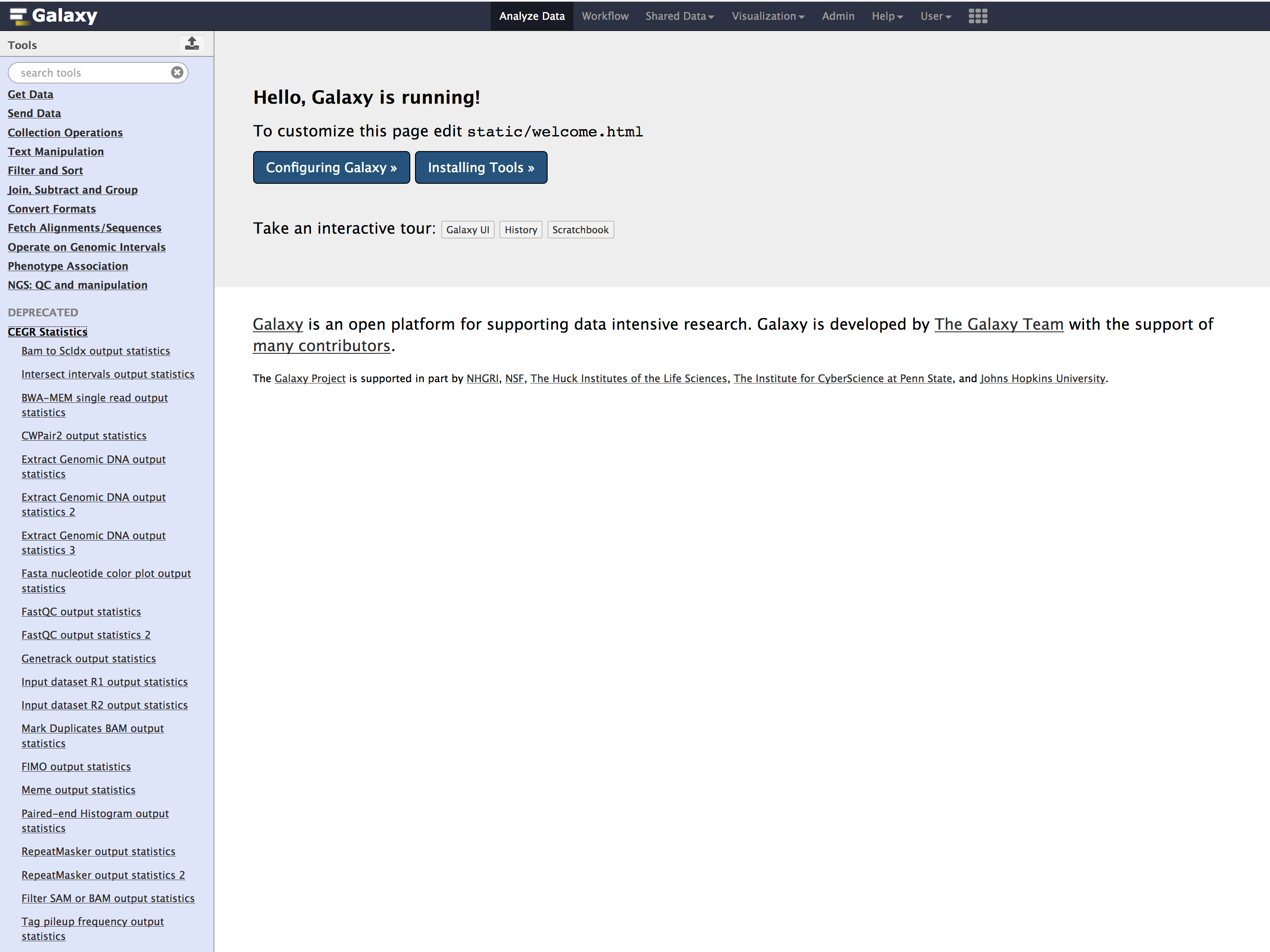
Congratulations!you have successfully installedoutput_statisticstools into your galaxy.
Connecting Galaxy to PEGR
Galaxy and PEGR communicate with each other using API keys. If you have not setup a local developmental PEGR. Set it up using these instructions & come back to this section
In the above section we installed output_statistics tools. These are the tools that send back information to PEGR. We did not configure the tools in the above section, which we will do in this section.
Changing Galaxy's port
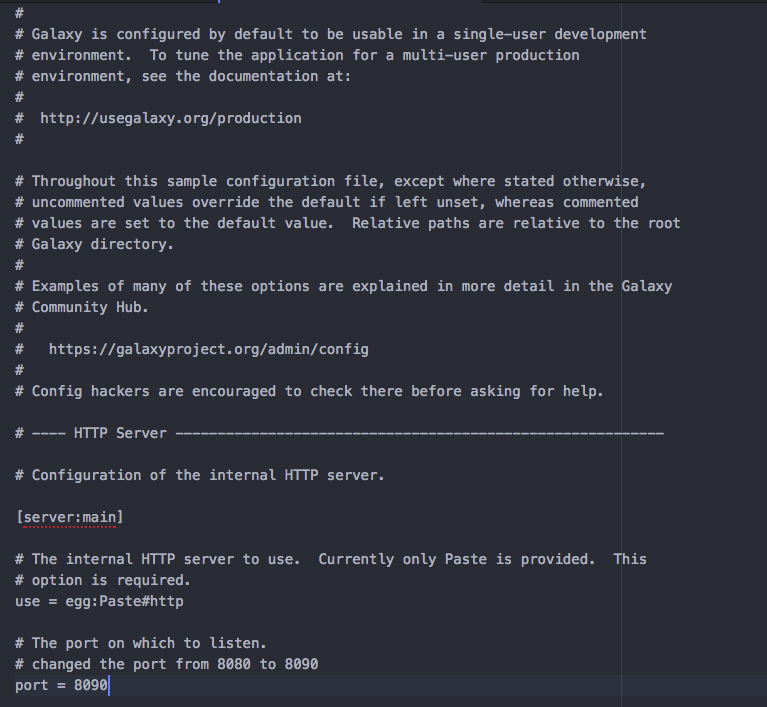
- First, we will configure
Galaxyto run on a differentportso that it does not conflict withPEGR's default port. - Open
galaxy/config/galaxy.iniin a text editor and search forportsetting. Change the port to8090. Below image shows the change ingalaxy.ini.
Generating Galaxy API key
- Click on
Admintab, underUser Managementsection, click onAPI keys. - Click on
Generatebutton to create an API key. Don't regenerate a new key, if you already have one at this point.
CEGR output_statistics configuration
- Open
galaxy/tools/stats_config.ini.sampleand add below information
# Configuration file for the CEGR Galaxy ChIP-exo statistics tools.
[defaults]
# This section contains default settings for command line parameters that
# can be overridden when they are passed to executed scripts.
PEGR_API_KEY = <REPLACE THIS WITH PEGR API KEY>
PEGR_URL = http://localhost:8080/pegr/api/stats
GALAXY_API_KEY = <REPLACE THIS WITH YOUR GALAXY ADMIN USER's API KEY>
GALAXY_BASE_URL = http://localhost:8090
[tool_categories]
input_dataset_r1 = output_fastqRead1
input_dataset_r2 = output_fastqRead2
toolshed.g2.bx.psu.edu/repos/iuc/bam_to_scidx/bam_to_scidx/1.0.1 = output_bamToScidx
toolshed.g2.bx.psu.edu/repos/iuc/bedtools/bedtools_intersectbed/2.27.0.0 = output_bedtoolsIntersect
toolshed.g2.bx.psu.edu/repos/devteam/bwa/bwa_mem/0.7.17.1 = output_bwaMem
toolshed.g2.bx.psu.edu/repos/iuc/cwpair2/cwpair2/1.1.0 = output_cwpair2
toolshed.g2.bx.psu.edu/repos/iuc/genetrack/genetrack/1.0.1 = output_genetrack
toolshed.g2.bx.psu.edu/repos/iuc/extract_genomic_dna/Extract genomic DNA 1/3.0.3 = output_extractGenomicDNA
toolshed.g2.bx.psu.edu/repos/devteam/fastqc/fastqc/0.70 = output_fastqc
toolshed.g2.bx.psu.edu/repos/iuc/pe_histogram/pe_histogram/1.0.1 = output_peHistogram
toolshed.g2.bx.psu.edu/repos/bgruening/repeat_masker/repeatmasker_wrapper/0.1.2 =output_repeatMasker
toolshed.g2.bx.psu.edu/repos/iuc/meme_meme/meme_meme/4.11.2.0 = output_meme
toolshed.g2.bx.psu.edu/repos/iuc/fasta_nucleotide_color_plot/fasta_nucleotide_color_plot/1.0.1 = output_fourColorPlot
toolshed.g2.bx.psu.edu/repos/jjohnson/samtools_filter/samtools_filter/1.1.1 = output_samtoolFilter
toolshed.g2.bx.psu.edu/repos/devteam/picard/picard_MarkDuplicates/2.7.1.1 = output_markDuplicates
toolshed.g2.bx.psu.edu/repos/iuc/meme_fimo/meme_fimo/4.11.2.0 = output_fimo
toolshed.g2.bx.psu.edu/repos/iuc/tag_pileup_frequency/tag_pileup_frequency/1.0.1 = output_tagPileup
- Below is an example configuration, after you add your API Keys.
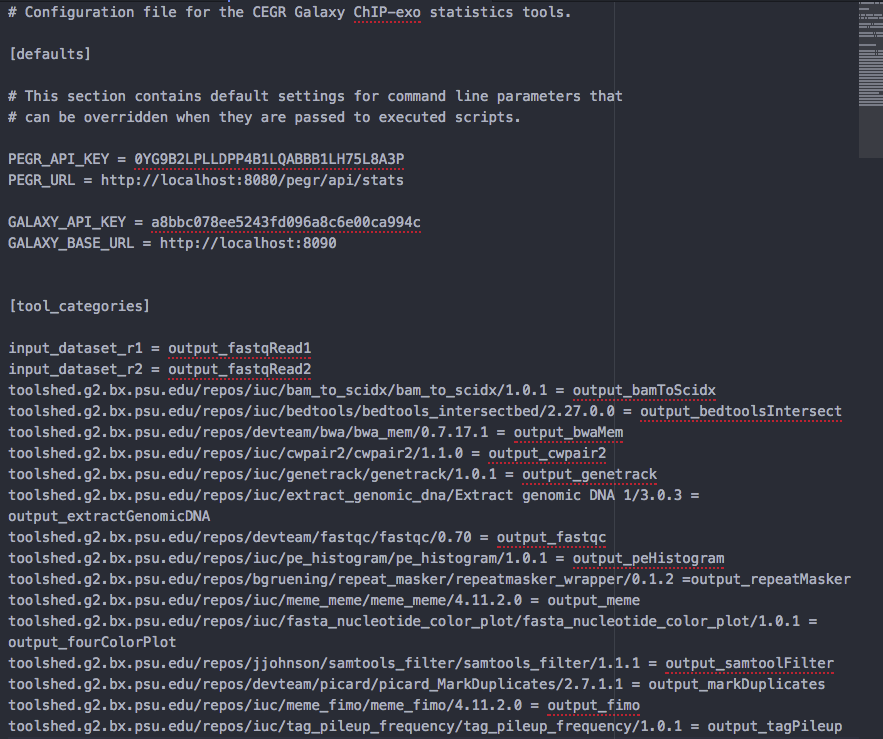
- Rename
stats_config.ini.sampletostats_config.ini
Install bioblend
bioblend is a python library to interact with Galaxy, using APIs
- Installation instructions here
- If you have already installed
Anaconda&pippip install bioblend
- Using bioblend docs
Adding core-sequencing workflowId into your local development PEGRdb
This step is important, as it lets PEGR know which workflow stats to accept and update on PEGR web frontend
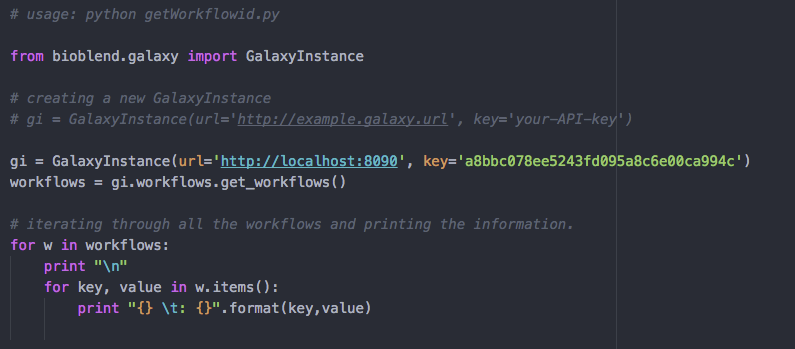
- Download
getWorkflowid.pyfrom link removed:./image/data/getWorkflowid.py - Open the script and replace the
urlandkeywith your local galaxy url and API key respectively. After adding your API-key, looks like the below image:
- Start your galaxy
- Run the script to retrieve the workflowId. Below is an image showing expected output
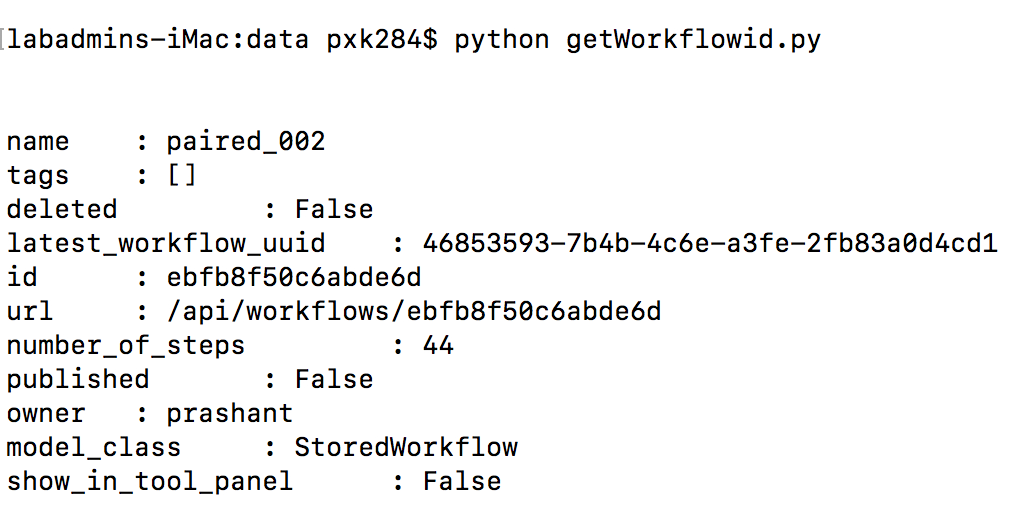
- Your workflow id is
ebfb8f50c6abde6din the above example. - Start your
MySQLserver and log into it using the username and password that you used while setting upPEGRor you can login as rootmysql -u root -p
use pegr;
describe pipeline;
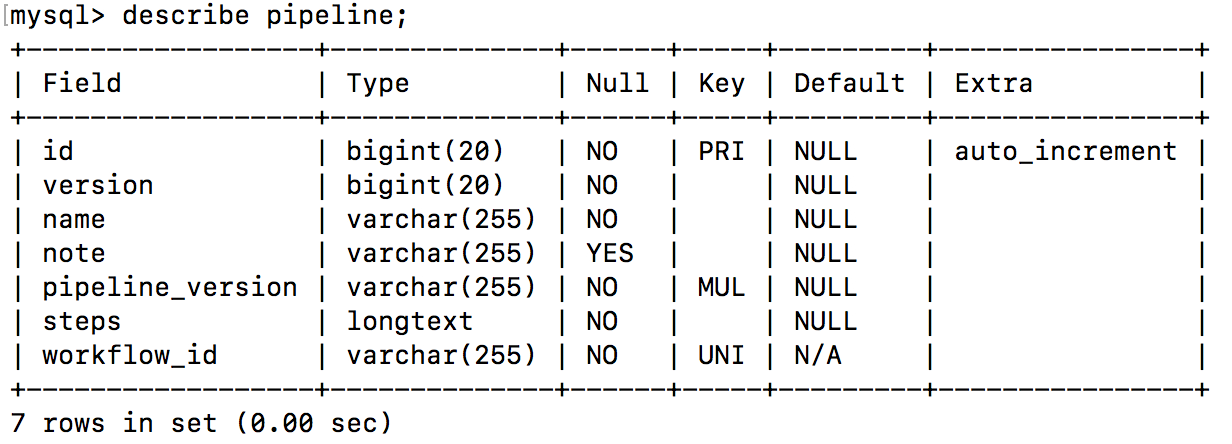
- Edit below query with a
pipeline-nameof your choice and add theworkflowidyou retrieved from above script and execute it. Below is an example query that you need
insert into pipeline( version,name,note,pipeline_version,steps,workflow_id)
values( 1,
'<pipeline-name>',
'Locally installed galaxy sending JSON dictionaires to locally installed pegr','001', '[["input_dataset_r1_output_stats","fastqRead1"],["input_dataset_r2_output_stats","fastqRead2"],["fastqc_output_stats","fastqc"],["fastqc_output_stats2","fastqc"],["mark_duplicates_bam_output_stats","markDuplicates"],["samtool_filter2_output_stats","samtoolFilter"],["pe_histogram_output_stats","peHistogram"],["bam_to_scidx_output_stats","bamToScidx"],["genetrack_output_stats","genetrack"],["bedtools_intersectbed_output_stats","bedtoolsIntersect"],["cwpair2_output_stats","cwpair2"],["extract_genomic_dna_output_stats","extractGenomicDNA"],["extract_genomic_dna_output_stats2","extractGenomicDNA"],["repeatmasker_wrapper_output_stats","repeatMasker"],["repeatmasker_wrapper_output_stats2","repeatMasker"],["meme_meme_output_stats","meme"],["meme_fimo_output_stats","fimo"],["extract_genomic_dna_output_stats3","extractGenomicDNA"],["fasta_nucleotide_color_plot_output_stats","fourColorPlot"],["tag_pileup_frequency_output_stats","tagPileup"]]' ,
"<workflowid>");
- This how your query looks like after adding your pipeline-name and workflowid

- You are all set for executing the pipeline. (if you have followed and set up the keys correctly, there should be no errors)